Difference between revisions of "Normal Accidents and Root Cause Analysis"
| Line 12: | Line 12: | ||
Normal accidents: | Normal accidents: | ||
| − | + | * 3 Mile Island Accident - Blamed Operators | |
| − | + | * Any system can and will fail, and you should plan for it to fail | |
| − | + | * 2 Axis graph | |
| − | + | ** Complexity -> Simple | |
| − | + | ** Loose Coupling -> Tight Coupling | |
| − | + | ** Complex & Tightly Coupled = Accident | |
| − | + | * Complex system that is Loosely coupled is the CITCON open space set up evening | |
| − | + | ** We did not all rush to get food and beer | |
| − | + | * E.g had there been a Lion in there, 1 person could have warned rest | |
| − | + | * Chance to warn of danger | |
| − | + | * Simple but tightly coupled = Dam | |
| − | + | ** Accident is water gets through the damn | |
| − | + | ** Anything goes wrong with dam e.g. hole, no chance to resolve | |
| − | + | ** Simple to reason about, wall of rock with a hole in | |
| − | + | ** But is high risk | |
| − | + | * In nuclear plant accident, cooling system near radioactive rods | |
| − | + | ** Operators can see there was a leak, but no context e.g. they can see the leak is leaking near/into the radioactive rod storage which would lead to an accident | |
| − | + | * Book to Read: Normal Accidents by Perrow | |
| − | + | * Are micro services tightly coupled and complex? | |
| − | + | ** Depends | |
| − | + | ** It's down to design and implementation | |
| − | + | * Always strive to be in the bottom right corner of the graph, low complexity loosely coupled | |
| − | + | * How do people plan for failure? | |
| − | + | ** Rob - We go through a certification process to get into Retail | |
| − | + | * Each system that could fail is tested, e.g. chaos monkey style someone will manually go take down services | |
| − | + | * Internal team will run same tests internally before handing over to external certification team | |
How do you verify or even test your logging? Instance of a service that logged every time on failure, in a tight loop and filled the disks leading to further failure = Simple Tightly Coupled System | How do you verify or even test your logging? Instance of a service that logged every time on failure, in a tight loop and filled the disks leading to further failure = Simple Tightly Coupled System | ||
| Line 46: | Line 46: | ||
Scenario: Database deliberately down for maintenance. Instance of a service that logged every time on failure connecting to database, in a tight loop and filled the disks leading to further failure | Scenario: Database deliberately down for maintenance. Instance of a service that logged every time on failure connecting to database, in a tight loop and filled the disks leading to further failure | ||
| − | + | * Basic principals | |
| − | + | ** Everybody who was affected comes to the meeting | |
| − | + | * To identity cultural or people problems | |
| − | + | * Not allowed to place blame | |
| − | + | * Ask/poll everyone what was the problem | |
| − | + | ** Customer: | |
| − | + | *** No system, was down, can't log on | |
| − | + | ** Operations: | |
| − | + | *** Confused by phone call | |
| − | + | ** Customer Service: | |
| − | + | *** Angry calls from customers, did not know what was going on | |
| − | + | ** Developer: | |
| − | + | *** Database down, no disk space | |
| − | + | *** Then ask why: | |
| − | + | ** Customer: | |
| − | + | ** Operations: | |
| − | + | ** Customer Service: | |
| − | + | ** Developer: | |
· Why: Maintenance on database, database down | · Why: Maintenance on database, database down | ||
· Why: Analysed log files, saw huge files, checked code, logged with no delay | · Why: Analysed log files, saw huge files, checked code, logged with no delay | ||
Revision as of 01:58, 21 September 2014
Normal Accidents book: http://press.princeton.edu/titles/6596.html
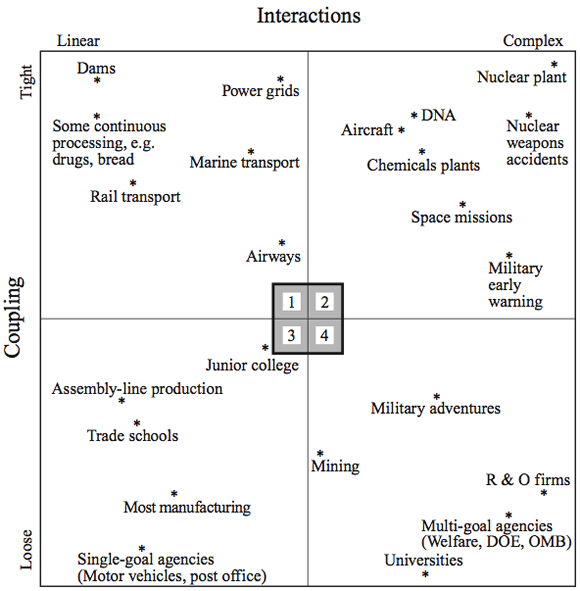
Systems are categorized by Interactions that are Simple vs Complex, and Tightly Coupled vs Loosely Coupled.
There are a few different versions of the quadrant: http://paei.wdfiles.com/local--files/perrow-charles-normal-accident-theory/PAEI_043_Perrow_Normal_Accident_Theory.gif https://www.flickr.com/photos/metanick/139214026/ http://media.peakprosperity.com/images/3-Perrow-from-Accidents-Normal.png
{kind=link}
{kind=link}
Douglas Squirrel talking about root-cause analysis: https://skillsmatter.com/skillscasts/1986-talk-by-squirrel
Notes on Squirrel's talk: http://www.markhneedham.com/blog/2011/12/10/the-5-whysroot-cause-analysis-douglas-squirrel/
Notes from John Bradshaw:
Normal accidents:
- 3 Mile Island Accident - Blamed Operators
- Any system can and will fail, and you should plan for it to fail
- 2 Axis graph
- Complexity -> Simple
- Loose Coupling -> Tight Coupling
- Complex & Tightly Coupled = Accident
- Complex system that is Loosely coupled is the CITCON open space set up evening
- We did not all rush to get food and beer
- E.g had there been a Lion in there, 1 person could have warned rest
- Chance to warn of danger
- Simple but tightly coupled = Dam
- Accident is water gets through the damn
- Anything goes wrong with dam e.g. hole, no chance to resolve
- Simple to reason about, wall of rock with a hole in
- But is high risk
- In nuclear plant accident, cooling system near radioactive rods
- Operators can see there was a leak, but no context e.g. they can see the leak is leaking near/into the radioactive rod storage which would lead to an accident
- Book to Read: Normal Accidents by Perrow
- Are micro services tightly coupled and complex?
- Depends
- It's down to design and implementation
- Always strive to be in the bottom right corner of the graph, low complexity loosely coupled
- How do people plan for failure?
- Rob - We go through a certification process to get into Retail
- Each system that could fail is tested, e.g. chaos monkey style someone will manually go take down services
- Internal team will run same tests internally before handing over to external certification team
How do you verify or even test your logging? Instance of a service that logged every time on failure, in a tight loop and filled the disks leading to further failure = Simple Tightly Coupled System
Root Cause Analysis
Scenario: Database deliberately down for maintenance. Instance of a service that logged every time on failure connecting to database, in a tight loop and filled the disks leading to further failure
- Basic principals
- Everybody who was affected comes to the meeting
- To identity cultural or people problems
- Not allowed to place blame
- Ask/poll everyone what was the problem
- Customer:
- No system, was down, can't log on
- Operations:
- Confused by phone call
- Customer Service:
- Angry calls from customers, did not know what was going on
- Developer:
- Database down, no disk space
- Then ask why:
- Customer:
- Operations:
- Customer Service:
- Developer:
- Customer:
· Why: Maintenance on database, database down · Why: Analysed log files, saw huge files, checked code, logged with no delay · Why: Developer skills lacking · Why: No code review/inspection · Why: Test for this logging case lacking · When QA tested database was running · QA too busy to investigate database failures cases · No new blood in organisation · QA assigned/overbooked to too many projects · Action: Maintenance on DB, have redundant database to switch to · Action: QA involved earlier
§ Actions must be assigned and completed with a timeframe e.g. 1 week § When you hit that uncomfortable silence half way down, keep pushing
· The root cause of failure is always the culture in an organisation
o It’s always about people e.g.
· The developer adding no delay to logging
· Lack of testing
· Create a RCA timeline of failure
o At what time did system go down
o At what time did customers complain
o At what time did developers react
o At what time was the system back up
o Etc
· Do as much technical investigation as possible before the RCA meeting
o Eg this was the problem
o We had these tests
· But we didn’t have one for this scenario